Researcher
My research interests include semi-parametric statistics in survival analysis and usable metrics that reshape how we approach research. See the tabs below to view my past and present projects!
My PhD research focuses on survival analysis, with an emphasis on semiparametric methods. I enjoy these techniques because they balance interpretability and flexibility, enabling robust modeling of complex data.
Semiparametric Linear Regression under Left-Truncation and Right-Censoring
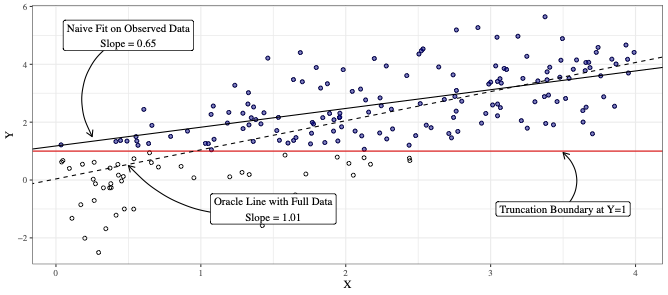
Brief Abstract: We propose a semiparametric sieve likelihood approach for fitting linear regression models to data with both left-truncation and right-censoring, common in cohort studies of disease onset. Our method yields consistent, asymptotically normal, and semiparametrically efficient estimators, as demonstrated through simulations across various error distributions. We illustrate its effectiveness with an application to The 90+ Study on aging and dementia.
Notes and Links:
- Paper (coming soon) (Submitted to Statistics in Medicine)
- Paper code and
ltrcR Package
Asymptotic Distributional Theory for Spline Estimates
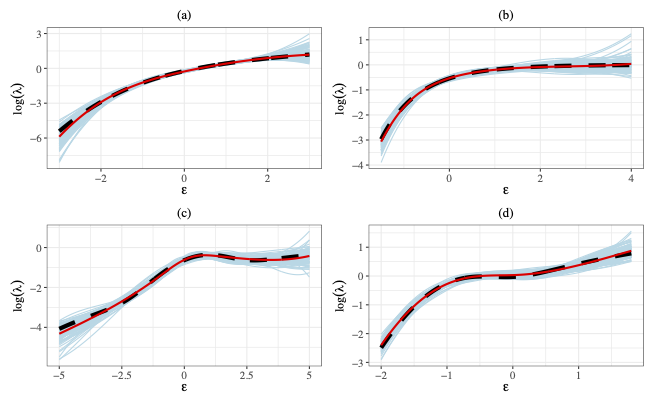
Brief Abstract: Building on results from the project above, we aim to establish a general theorem for the joint normality of spline parameter estimates in semiparametric models. Key challenges include handling bundled parameters, controlling spline approximation error, and addressing high dimensionality as the number of knots increases with sample size. Leveraging insights from random matrix theory, we will apply our results to semiparametric linear models and the Cox model to demonstrate their practical utility.
Notes and Links:
- Work in Progress with planned completion in the Spring of 2026
I am passionate about developing tools that enable researchers to study healthspan. The Golden Health Index and related projects represent my first steps toward this goal.
Introducing the Golden Health Index
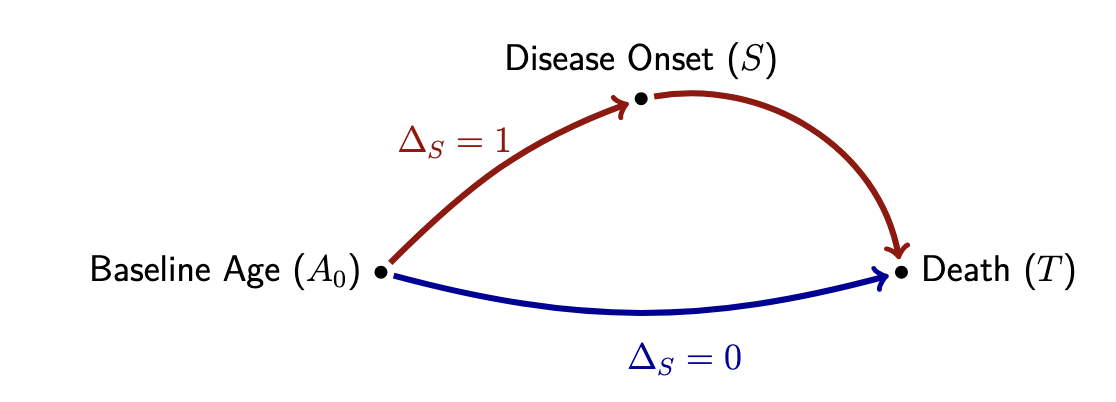
Brief Abstract: We introduce a novel framework for analyzing age-related disease data, presenting three key metrics that capture disease dynamics in a population. Using data from the National Alzheimer’s Disease Coordinating Center, we illustrate these metrics and demonstrate differences in the Golden Health Index based on APOE E4 allele count.
Notes and Links:
- Paper (coming soon)
- Code (coming soon)
- Slides (coming soon)
The Golden Health Index: The Regression Case under Left-Truncation
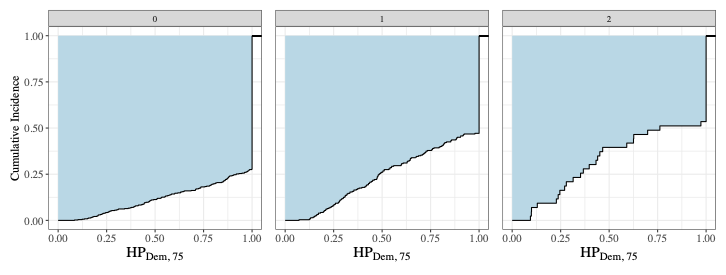
Brief Abstract: We address left-truncation and the regression case for the previously introduced metric: The Golden Health Index. We present theoretical results, simulations, and an application to the NACC dataset, demonstrating its utility in analyzing population health trajectories and identifying risk factors for accelerated decline.
Notes and Links:
- Paper (coming soon)
- Code (coming soon)
- Slides (coming soon) (to be presented at WNAR 2025)
My research is driven by real-world problems, and I enjoy collaborating across disciplines. From medicine to finance, these projects showcase how I apply statistical methods to diverse fields.
SAD Money: Using Survival Analysis Divergence fo Evaluate and Refine Financial Time Series Generation
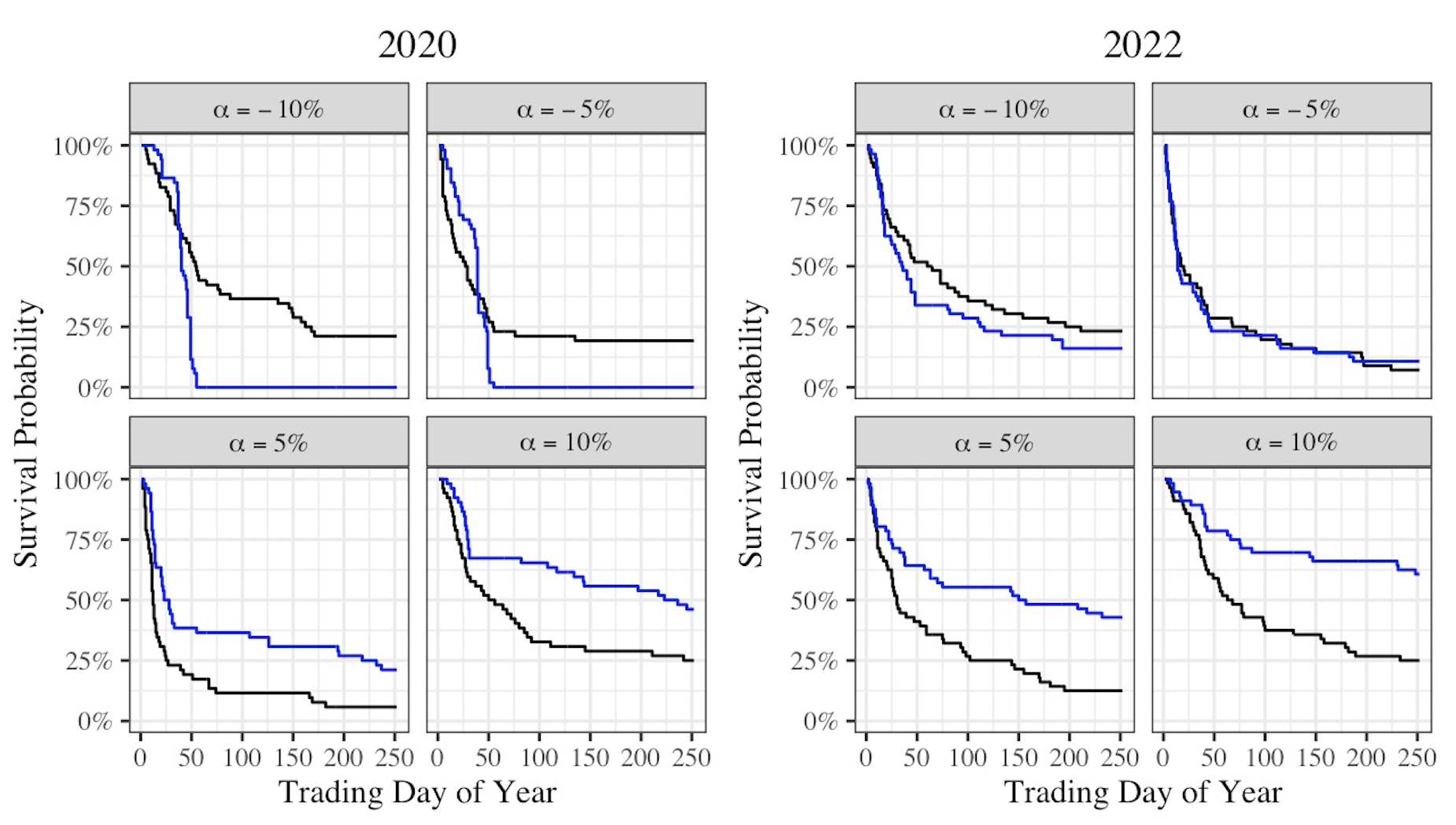
Brief Abstract: Synthetic financial time series generation has primarily focused on high-frequency trading, leaving longer-term portfolio management underexplored. We propose a framework with a novel evaluation metric to improve the fidelity of synthetic data for long-term investors. This approach enables more realistic stochastic backtesting, helping investors refine portfolio strategies over extended time horizons.
Notes and Links:
- Extended Abstract (accepted for refereed presentation at SDSS 2025)
- Talk Slides (Coming Soon)
- Talk Transcript (Coming Soon)
Impact of COVID-19 on Long-Term Neuropsychological Functioning in Older Adults
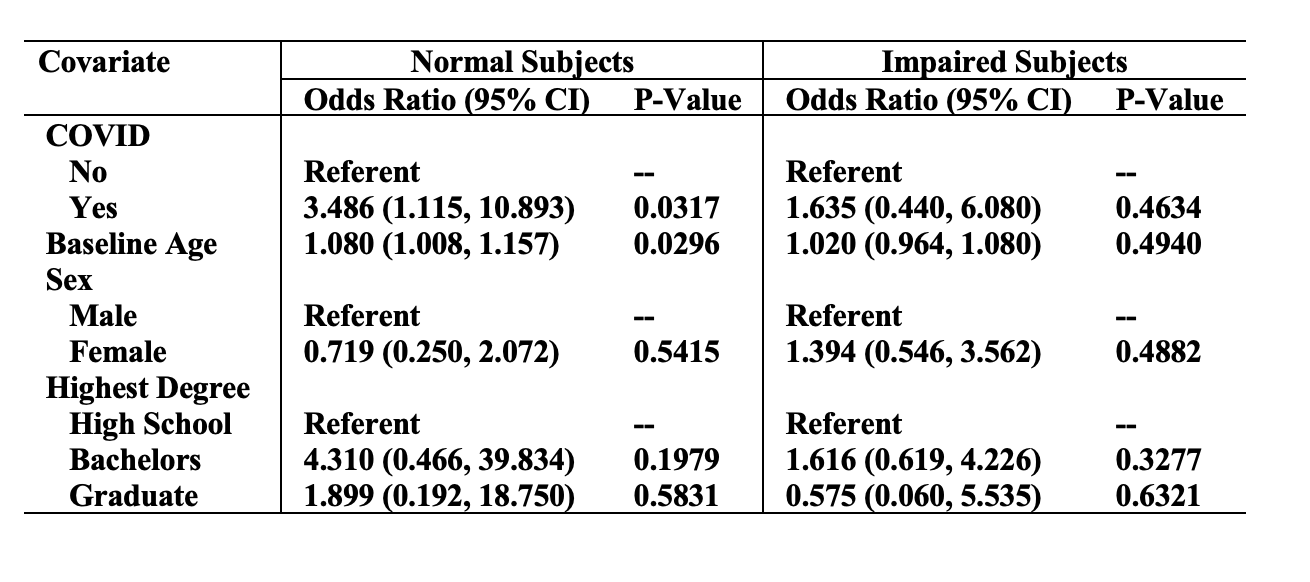
Brief Abstract: We examined whether COVID-19 was associated with cognitive decline in older adults using data from the UC Irvine Alzheimer’s Disease Research Center. No increased risk of cognitive diagnosis changes or significant declines in neuropsychological tests were observed. These findings suggest that older adults do not experience long-term cognitive decline after COVID-19 based on a comprehensive evaluation of functional and cognitive abilities.
Notes and Links:
- Joint work with Arunima Kapoor, David L. Sultzer, Michelle McDonnell, and Bin Nan
- Paper (coming soon)
Investigating Functional Differences in NT5c1A seropositive and seronegative IBM participants in the INSPIRE-IBM Trial
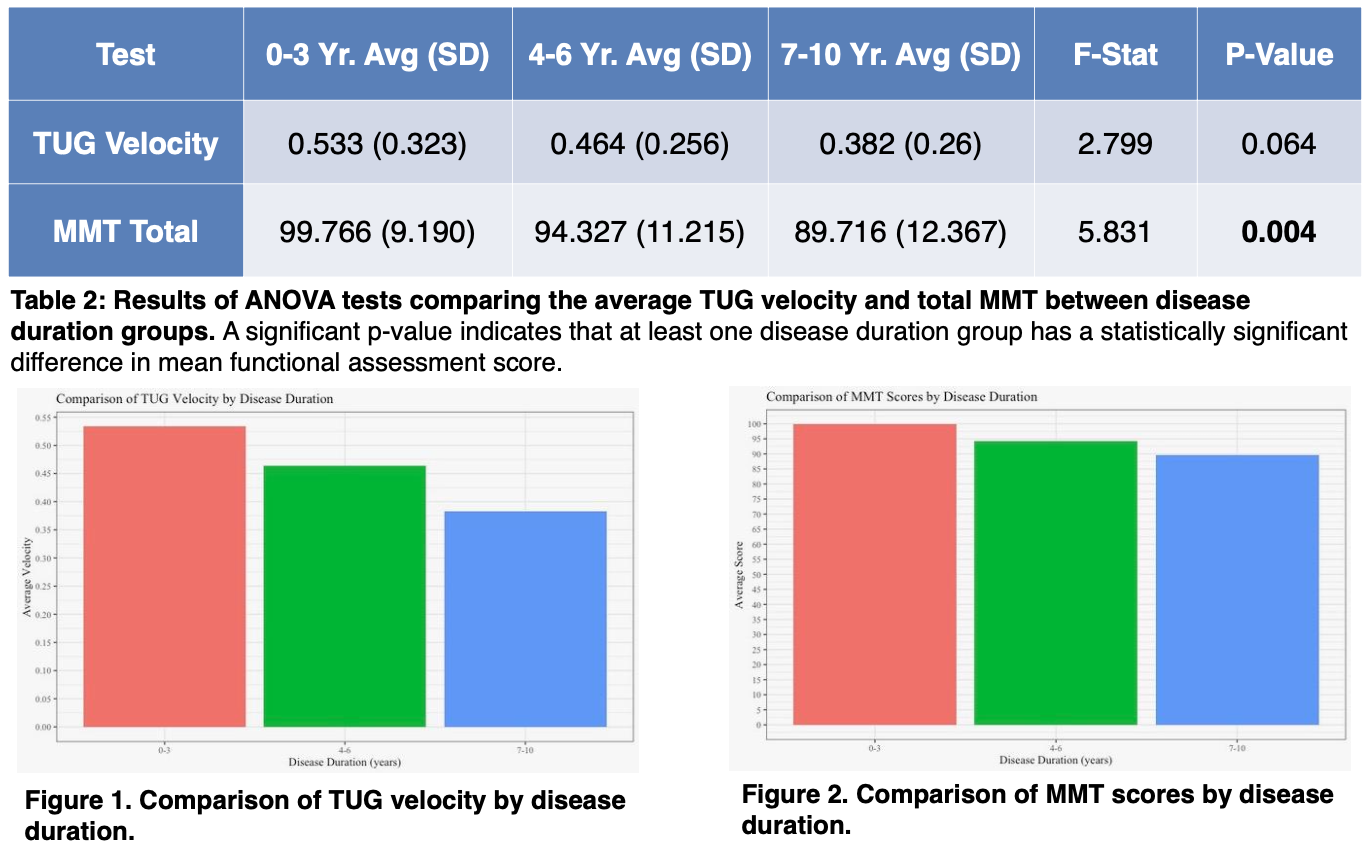
Brief Abstract: Inclusion body myositis (IBM) is a progressive muscle disease affecting individuals over 40, with an annual strength decline of 3.5–5.4%. Anti-NT5c1A antibodies serve as a potential biomarker, but their relationship to disease severity remains unclear, with conflicting studies suggesting either a more severe phenotype in seropositive patients or no significant differences. These findings highlight the need for further research into IBM’s clinical features while accounting for serological status and disease duration.
Notes and Links:
What Kinds of Doubles Volleyball Partnerships are Successful?
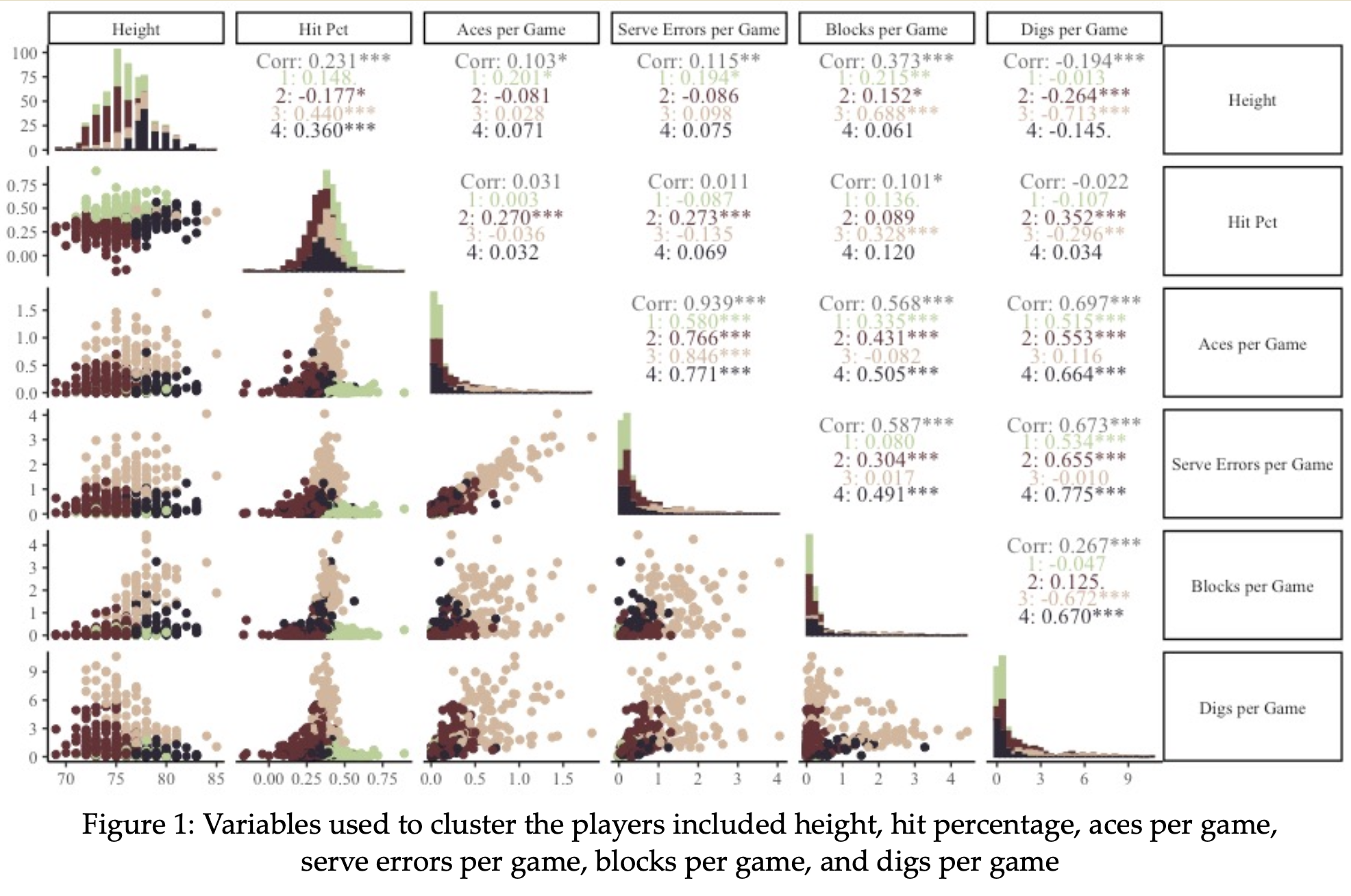
Brief Abstract: We analyze data from men's professional beach volleyball leagues to classify players into four groups using k-means clustering and assess which pairings lead to the most success. While two player groups perform best with partners from the same group, the other two thrive with different-group partners. We examine key metrics in the most successful pairings and discuss future applications of this approach.
Notes and Links:
- Poster (presented at UCONN Sports Analytics Symposium 2021)
As an undergraduate, I conducted actuarial research under Dr. Dennis Tolley and Dr. Brian Hartman. With Dr. Hartman, I worked on projects using a large dataset from the CAS, exploring new approaches to insurance modeling.
Machine Learning in Ratemaking, an Application in Commercial Auto Insurance
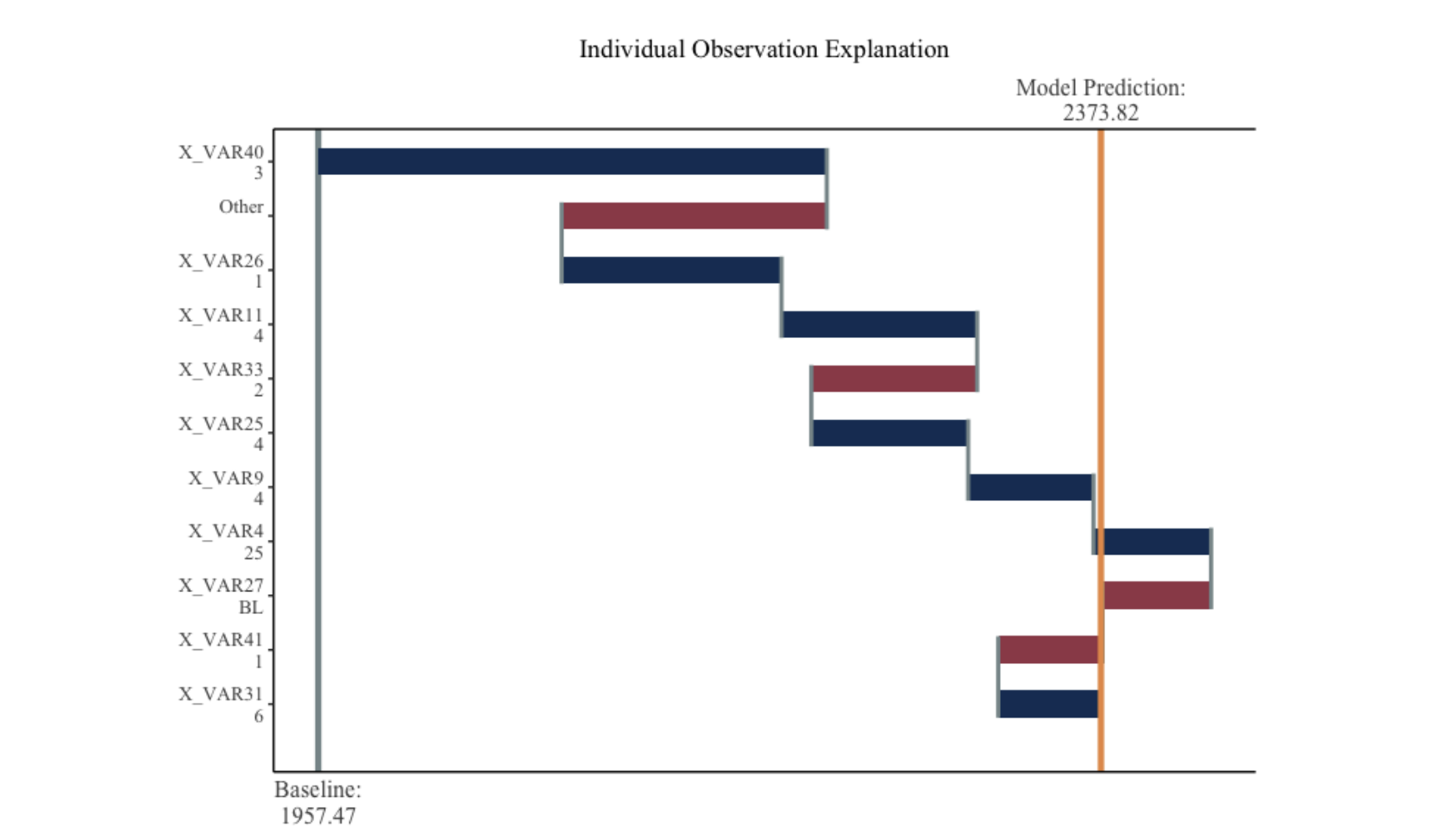
Brief Abstract: This paper examines the tuning and performance of two-part models on insurance datasets from the Casualty Actuarial Society (CAS), covering bodily injury, property damage, and collision claims. After exploring and summarizing the data, we tune and train models, analyzing select predictions. Our approach provides a foundation for future ratemaking models to be developed and tested more efficiently.
Notes and Links:
mSHAP: SHAP values for Two-Part Models
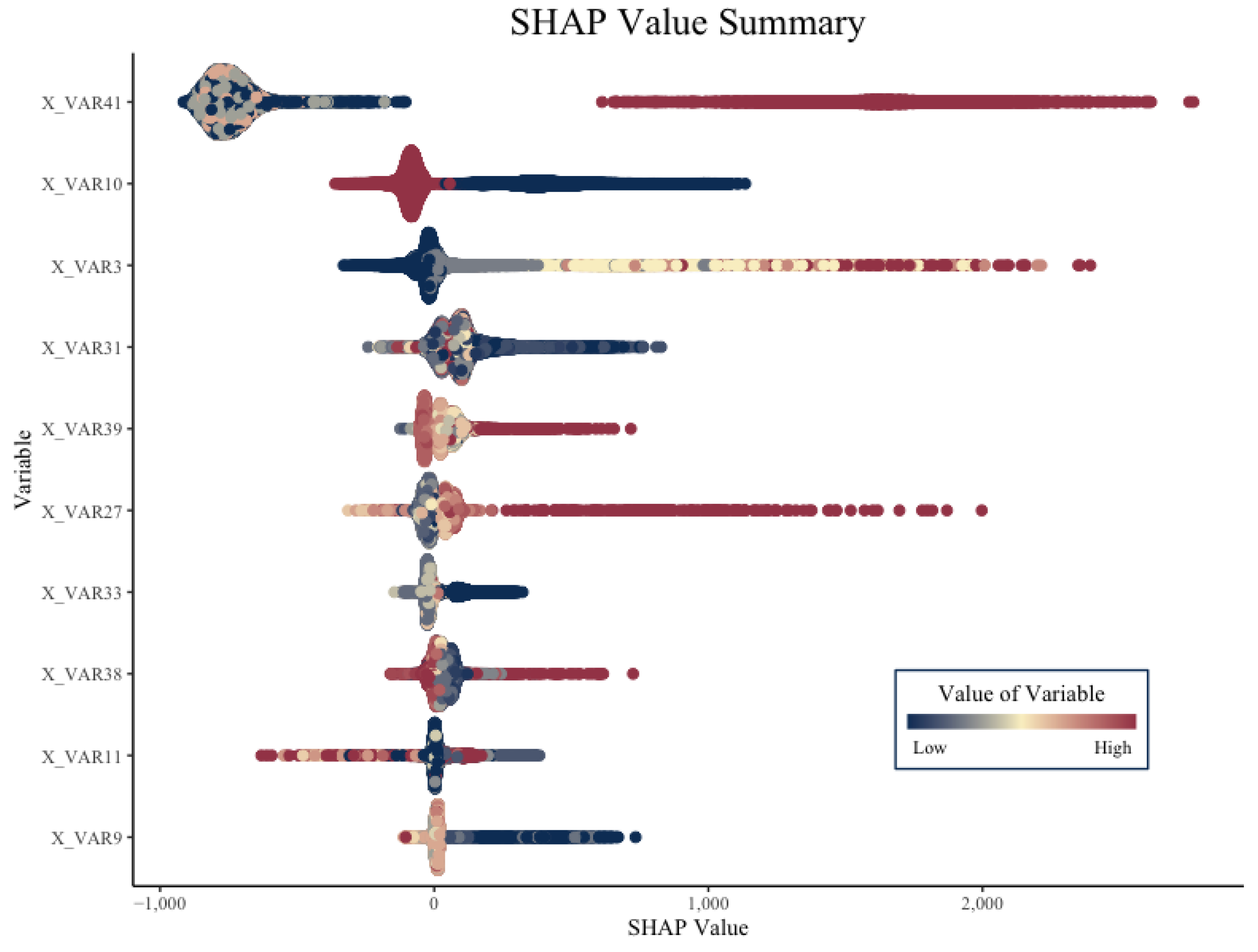
Brief Abstract: We propose mSHAP, a fast method for computing SHAP values in two-part insurance models, improving interpretability and reducing model risk. Our approach outperforms kernelSHAP and is applied to auto insurance pricing, with an R package (mshap) available for broader use.
Notes and Links: